Middelværdi, Varians og Spredning
Når man finder middelværdien af et datasæt, svarer det til at finde gennemsnittet at tallene. Man skriver det oftest som et x med en streg over
$$\overline{x}=\text{middelværdi}$$
Hvis vi havde spurgt 10 gymnasieelever om deres lommepenge og fået svarene at 5 fik 50kr/uge, 3 fik 70kr/uge og 2 fik 90kr/uge, så ville det gennemsnitlige antal lommepenge pr uge være
$$\overline{x}=\frac{50+50+50+50+50+70+70+70+90+90}{10}=64$$
Det vi gjorde, da vi regnede middelværdien ud, var at finde summen af alle observationerne (640). Herefter dividerede vi til sidst med det totale antal observationer (10).
Dette leder os frem til følgende formel
$$\overline{x}=\frac{1}{N}\sum_{i=1}^Nx_i=\frac{x_1+x_2+...+x_N}{N}$$
I eksemplet ovenfor er N=10, x1=70, x2=90 osv.
Da vi i dag ofte benytter os af computere og diverse matematikværktøjer(TI-nSpire, Maple) eller programmeringssprog (Python, Matlab, R, osv.), så vil man finde middelværdien ved følgende
$$ mean(x) = \frac{1}{N} sum(X) $$
hvor N er antallet af observationer (kan også defineres som length(X)) og x er en vektor(datarække, f.eks. en række eller kolonne i et regneark), der indeholder N værdier.
(Du kan læse mere om summationstegnet her)
Man kan også udregne middelværdien ved at gange frekvensen med observationen og summe det sammen
$$\overline{x}=\sum_{i=1}^nf_i\cdot x_i=f_1\cdot x_1+f_2\cdot x_2+...+f_n\cdot x_n$$
Man finder frekvensen ved
$$ f_i = \frac{h_i}{N} $$
hvor f er frekvensen for observationen, h er hyppigheden af observationen og N er det samlede antal observationer. Altså er frekvensen den procentdel observation i udgør af datasættet.
I ovenstående eksempel fik 50% af eleverne 50kr/uge, 30% fik 70kr/uge og 20% fik 90kr/uge. Altså kunne man have udregnet gennemsnittet som
$$\overline{x}=0,50\cdot50+0,30\cdot70+0,20\cdot90=64$$
Formlerne ovenfor kan vi bruge, når vi har med ugrupperede observationer at gøre. Men hvad gør vi så, når observationerne er grupperede?
Middelværdi for grupperede observationer
Når ens observationer er grupperede, kan man ikke bare tage og gange observationsværdien med hyppigheden. For observationerne er jo hele intervallet og ikke bare en enkelt værdi.
Det, man gør, er, at man udplukker midtpunktet af sit interval og bruger som observationsværdi. Når man finder middelværdien for grupperede observationer, så finder man ikke den rigtige middelværdi, men et estimat af middelværdien. Hvis ens interval har endepunkterne a og b, finder man altså midtpunktet på følgende måde:
$$m=\text{startværdi}+\text{halvdelen af intervallets længde}=a+\frac{b-a}{2}=\frac{a+b}{2}$$
eller
$$m=\text{slutværdi}-\text{halvdelen af intervallets længde}=b-\frac{b-a}{2}=\frac{a+b}{2}$$
Vi har altså formlen for intervalmidtpunktet:
$$m=\frac{a+b}{2}$$
Når man har fundet sit intervalmidtpunkt, sætter man det ind på xi'ernes plads i formlerne for middelværdien af de ugrupperede observationer. Altså får vi
$$\overline{x}=\frac{1}{N}\sum_{i=1}^N m_i=\frac{m_1+m_2+...+ m_N}{N}$$
eller hvis man hellere vil bruge frekvenserne:
$$\overline{x}=\sum_{i=1}^nf_i\cdot m_i=f_1\cdot m_1+f_2\cdot m_2+...+f_n\cdot m_n$$
Lad os se på et eksempel, hvor vi har målt højden af 25 elever.
| Observation, xi | Midtpunkt, mi |
Antal observationer i intervallet | Frekvens, f |
| ]160;170] | 165 | 8 | 32% |
| ]170;180] | 175 | 11 | 44% |
| ]180;190] | 185 | 6 | 24% |
Så kan gennemsnitshøjden beregnes vha. de to formler ovenfor:
Nu kan vi summere antallet af observationer i hvert interval, så vi får følgende
$$ \sum_{i=1}^{N} m_{i,[160;170]} \\ = 165+165+165+165+165+165+165+165 = 1320 $$
Vi laver regnestykket for hvert interval og får så
$$\overline{x}=\frac{1320+1925+1110}{25}=174,2$$
$$\overline{x}=0,32\cdot165+0,44\cdot175+0,24\cdot185=174,2$$
Varians og spredning
Varians og spredning siger noget om, hvor stor spredning, der er i datasættet. Ligger observationerne kort eller langt fra middelværdien?
Varians betegnes Var(x) eller med \( \sigma^2(x)\) (det græske bogstav lille sigma sat i anden). Man beregner variansen på følgende måde
$$\text{Var}(x)=\sigma^2(x)=\frac{1}{N}\sum_{i=1}^N(x_i-\overline{x})^2=$$
$$=\frac{(x_1-\overline{x})^2+(x_2-\overline{x})^2+...+(x_N-\overline{x})^2}{N}$$
$$\text{Var}(x)=\sigma^2(x)=\sum_{i=1}^nf_i(x_i-\overline{x})^2=$$
$$=f_1(x_1-\overline{x})^2+f_2(x_2-\overline{x})^2+...+f_n(x_n-\overline{x})^2$$
Man finder altså afstanden mellem hver observation og middelværdien. Denne kvadrerer man, og så finder man gennemsnittet af dette.
Spredningen (eller standardafvigelsen) betegnes \(\sigma(x)\). Læg mærke til, at spredning og varians begge betegnes med det græske bogstav sigma, (\(\sigma\)), hvor den eneste forskel er, at variansen er opløftet i anden. Spredningen beregnes på følgende måde
$$\sigma(x)=\sqrt{Var(x)}=\sqrt{\sigma^2(x)}$$
Lad os finde varians og spredning for eksemplerne med lommepenge og højder ovenfor.
For lommepengeeksemplet er de:
$$\sigma^2(x)=0,50\cdot(50-64)^2+0,30\cdot(70-64)^2+0,20\cdot(90-64)^2=$$
$$=244$$
$$\sigma(x)=\sqrt{244}\approx15,62$$
og for højde-eksemplet er de
$$\text{Var}(x)=$$
$$0,32\cdot(165-174,2)^2+0,44\cdot(175-174,2)^2+0,24\cdot(185-174,2)^2$$
$$\approx55,36$$
$$\sigma(x)=\sqrt{55,36}\approx7,446$$
Bemærk, at vi brugte intervalmidtpunkterne til at finde variansen i tilfældet med grupperede observationer.
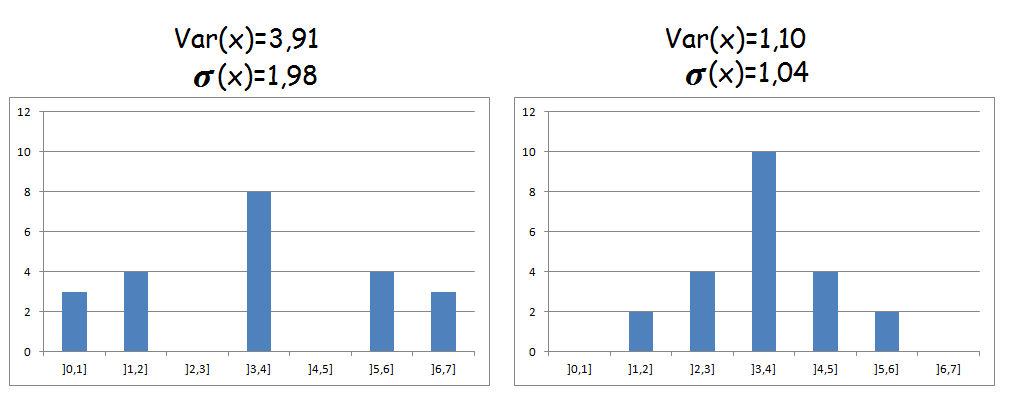
Man bruger tit spredning og varians til at sammenligne forskellige datasæt. Herunder er tegnet søjlediagrammer for to datasæt. Hver består af 22 observationer og de har samme middelværdi. Imidlertid er varians og spredning forskellig for de to datasæt.